LLM Reliability,
Control, and Audit
— as Infrastructure
A production-grade gateway that sits between your application and LLM providers, enforcing reliability, cost control, safety evaluation, and compliance.
THIS IS
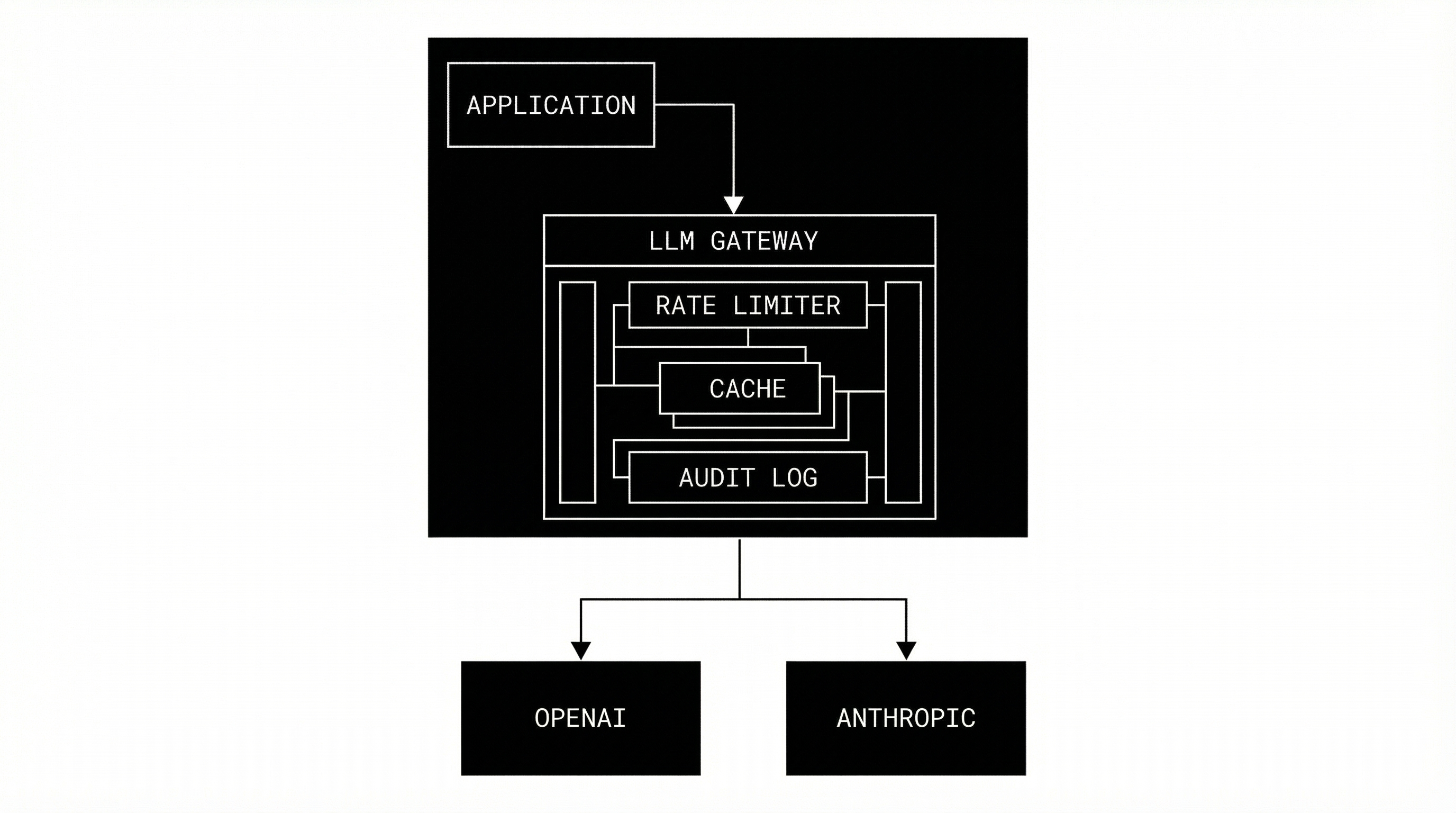
- 1An LLM GatewayCentralized control point for all LLM traffic.
- 2A Reliability Control PlaneEnforces guarantees before requests hit providers.
- 3Infrastructure LayerBackend-only middleware for your stack.
THIS IS NOT
- 1A Chat UINo frontend for end-users. API only.
- 2A Reasoning EngineWe don't think. We route and control.
- 3A RAG PlatformBring your own vector database.
LLMs are unreliable by default.
This system exists because production systems need guarantees that raw APIs cannot provide.
API Failures
429s, 5xx errors, and random outages are common.
Cost Explosions
Infinite loops and abuse can drain budgets in minutes.
Compliance Black Holes
No native audit trail for enterprise requirements.
Zero Visibility
Opaque usage patterns across engineering teams.
Unsafe Evaluations
No way to re-run evals without re-generating.
Tenant Leaks
Lack of isolation between different customer data.
Core Capabilities
Reliable LLM Proxy
Ensures requests complete even when providers stutter.
- Retries & Backoff
- Circuit Breakers
- Fail-open/closed logic
Rate Limiting
Granular control over traffic flow with Redis backing.
- Workspace-level
- API-key-level
- IP-level enforcement
Token & Cost Budgets
Prevent bill shock before the request is even sent.
- Hard enforcement
- Daily/Monthly limits
- Cost estimation
Safety Evaluation
Real-time analysis of inputs and outputs for safety.
- Heuristic checks
- LLM-as-judge
- Risk scoring
Immutable Audit Trail
Every interaction logged permanently for audit.
- Append-only DB
- DB-level triggers
- Compliance-ready
Evaluation Versioning
Track quality changes over time deterministically.
- Historical comparison
- Re-run capability
- No overwrites
Retention & Cleanup
Automated data lifecycle management.
- Scheduled jobs
- Per-workspace policies
- GDPR-ready
Observability
Deep visibility into system health and performance.
- Prometheus metrics
- Structured logs
- PII scrubbing
System Architecture
Async by Design
Request → Immediate Response → Background Evaluation. Critical path is decoupled from heavy analysis tasks.
Stack Components
- • Next.js Backend (Edge ready)
- • PostgreSQL + Prisma (Data layer)
- • Redis (Rate limiting & Queues)
- • BullMQ (Worker orchestration)
Observability
Prometheus-style metrics and Sentry error tracking integrated at the core.
Verification & Correctness
"If this breaks, we know exactly how and why."
Untrusted by Default
The system assumes failure. It is verified by rigorous tests, database constraints, and runtime assertions.
Failure Simulation
We test against Redis outages, DB locks, and provider downtime. Degraded modes are first-class citizens.
Strict Constraints
Unique keys, foreign key constraints, and DB-level triggers ensure data integrity cannot be compromised by app bugs.
Intentional Limitations
This is intentional.
Ideal For
- SaaS Teams building production AI features
- Infra-heavy products requiring guarantees
- Regulated environments (Fintech, Health)
- Cost-sensitive startups
Not For
- Hobbyists building chat bots
- Teams needing a "magic" solution
- Research/Academic experimentation
Deployment Philosophy
Dockerless First
Runs on bare metal or standard node environments.
Managed Services
Designed for managed Postgres & Redis.
Platform Agnostic
Deploy on Railway, Render, AWS, or VPS.
Env Driven
12-factor app configuration.
This system does not make LLMs smarter.
It makes them safe, observable, and controllable in production.